
Exercise 1: Software Security
Assignment Description
Next Deadline: Wednesday, May 8, 2024, 8:00am, Ex1 Deadline 2
Additional Information and Hints
This page is meant as additional information and hints, for questions not answered here, try one of the support channels.
The tools and code are generally made for Linux, though porting cacheutils to Windows is possible. We do not provide a windows library for task 4, you will need to develop this on linux. However, tasks 1-4 should work in WSL (with the exception of code that relies on virtual to physical memory translation, such as the Prime+Probe calibration tool).
Task 5 may or may not work in WSL, we recommend developing this on native Linux.
Similar to WSL, most things can be done in VMs, but in general we recommend solving the tasks on native Linux, to avoid any issues.
If you have both Intel and AMD available to you, you may find it easier to work on an Intel CPU. While all of the concepts used in this excercise should apply to both, some implementations (such as Prime+Probe in the demos folder) are configured for an Intel cache layout. If you encounter unexpected behaviour or are unsure about the CPU available to you, don’t hesitate to ask.
It is very helpful to use cpupower or cpufreq-utils to set the system to performance mode (”sudo cpupower -c all set -b 0”). It will make your results more reliable and reproducible.
Do not rely on the threshold the calibration tools suggest. We provided you with the knowledge to choose a good threshold for a reason. Use your knowledge and choose a good threshold on your own.
We recommend compiling with -Os or -O3 for best performance with cache attacks.
Whenever you iterate over memory – consider the prefetcher. It is the prefetcher’s job to load memory it thinks you will need into the cache. When you’re doing cache attacks, this will ruin your day.
On Intel, the prefetcher will recognize patterns within a page – on AMD even when accesses are spaced out over multiple pages!
Use the following code snippet to “randomize” the iterator i (here from 0 to 255) enough to confuse prefetchers:
int mix_i = ((i * 167) + 13) & 255
Use mix_i to index your memory instead of i.
Another annoying prefetcher is the adjacent line prefetcher. Whenever a line is (re)accessed, the adjacent line may be cached as well. Keep that in mind.
FAQ
- I’m on a Zen CPU, my F+R calibration works, but I don’t see anything on my covert channel between 2 threads, what’s going on?
Zen CPUs group cores together in packages, each with their own L3. This can mean that your CPU has more than 1 L3, and F+R won’t work accross them.
You can check which core uses which L3 by runninglscpu -e, the L3 column tell you what you need to know.
You can solve this problem by restricting your program to cores that share an L3, e.g. withtasket -c X,Y ./channel.
cacheutils.h
This file contains all the tools you should need for successful cache attacks.
The section “User configuration” contains the most important settings, the default cache miss timing and the timer to be used. On Intel CPUs,
The section “User configuration” contains the most important settings, the default cache miss timing and the timer to be used. On Intel CPUs,
rdtsc or rdtscp should both work fine. On newer AMD CPUs (>Zen), you may want to try rdpru for increased accuracy.Task 1 – Cache Histogram
Produce a Flush+Reload cache hit/miss histogram on at least one machine per team member, and submit a graphical plot into your repository.
Task 2 – Flush+Reload Attack on PIN entry
No hints yet 🙂
Task 3 – Cache Covert Channel
Spawn two different processes that communicate with each other via a cache covert channel. If you use Flush+Reload, this will include establishing some type of shared memory.
There are no restrictions on how you start the transmission initially (you may even write to shared memory), but once it has started, no more direct communication is allowed.
You may use any schemes to keep the processes synchronized, though we recommend the KISS principle.
Speed Records
| Group | Technique/Threads | Raw Capacity | Bit Error Ratio | True Capacity | CPU | Comments |
| Group 00 | Flush+Reload, 8 senders+8 receivers | 2320 kB/s | 0.63% | 2191 kB/s | i7-10700k |
Task 4 – Spectre
Familiarize yourself with the basic principle of Spectre-PHT, aka Spectre v1.
The library contains a branch that you can mistrain. If you do it right, you can then extract the secret with Flush+Reload, as explained in the lecture.
Start your implementation small! Try to leak only one known character in the beginning. Repeat the experiments often, and try different training parameters.
If you’re getting nothing but garbage, look at your cache threshold and the prefetcher tips.
If you see leakage but it is very slow, think about what you could do to slow down the branch you’re mistraining. What are its dependencies, can you stall them?
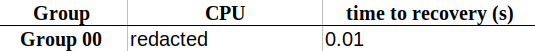
Task 5 – KASLR
The Linux Kernel is randomized to start at a page in the virtual address range 0xffffffff80000000 – 0xffffffffc0000000.
You can check if you found the correct offset with sudo cat /proc/kallsyms| grep startup_64.
If you are not able to detect the kernel, KPTI might be active on your system. Perform the following steps to disable it:
-edit /etc/default/grub (needs sudo) -add nopti to GRUB_CMDLINE_LINUX=““ -run sudo update-grub -reboot -cat /proc/cmdline should now show nopti somewhere
Don’t forget to remove this later, it’s a Meltdown mitigation.
Important: The behavior of AMD Zen 2 processors was modified, which can change how the attack needs to be performed. If you don’t have access to an earlier AMD processor or an Intel processor send an email to Lukas or ask in the discord SCS channel.
Speed Records
| Group | Time | Method | Reliability |
| Group 00 | 0.043s | Data Bounce | ~98.7% |